

해당 글은
경희대학교 조진성, 허선영 교수님의 강의 자료 및 내용을 정리한 글입니다
개인적으로 공부하며 작성된 글이라 잘못된 부분이 있을 수 있습니다!
오류가 있다면 알려주세요
Mass Storage
컴퓨터 시스템은 files, data를 영구적으로 보관하기 위해서 mass storage를 제공해야 합니다.
이때 여러 특징들이 존재할 수 있습니다.
Sequential access 🆚 Random access
Synchronous transfer 🆚 Asynchronous transfer
Dedicated 🆚Shared (한 시스템이 독점? 공유?)
Read-only 🆚 Read-write
Operating System은 해당 Mass stroage를 사용할 때
- 최대한 단순한 형태로 이용할 수 있게끔 하고,
- concurrency를 최대화하고자 I/O를 최적화 하는 것
에 목적이 있습니다.
Hard Disk Drive (HDDs)

magetically-coated되어 회전하는 platters가 쌓인 형태로 구성되어 있고,
read-write head를 움직여 정보를 읽습니다.
즉, 기계적인 움직임이 발생합니다.
Platter의 표면은 circular tracks로 나뉘고, 이는 고정된 크기의 sector로 또 나누어집니다.
주로 512 byte, 4kb를 sector의 크기로 지정하는데
이는 앞선 챕터에서 나온 Page 사이즈와 동일하게 처리하기 위함에 의도가 있다고 하네요.
Performance
Transfer Rate
drive와 computer 사이 data flow 속도
이론적으로 6기가바이트 /s
Positioning Time (Random-Access Time)
데이터를 읽기 위한 물리적인 움직임 시간
- Seek Time: 원하는 cylinder로 disk arm을 이동하는데 걸리는 시간
- Rotational Latency: 원하는 sector가 disk head의 아래에 위치하게끔 회전하는데 걸리는 시간
Access Latency
Average Seek Time + Average Rotational Latency
Average I/O Time = Access Time + Amout to Transfer/Transfer Rate + Controller Overhead
예시를 하나 들어봅시다.

7200 RPM(Revolution Per Minute) disk, 즉 1분에 7200회(1s 120)를 회전하는 하드디스크의
4KB block을 transfer하는데
- 5ms의 seek time
- 1Gb/s의 transfer rate
- 0.1ms의 controller overhead
이때 Transfer Time은

이때 KB(킬로바이트), Gb(기가비트)입니다.
이때 Average I/O Time은
seek time + rotation latency + controller overhead + transfer time으로

Nonvolatile Memory(NVM) Devices
데이터가 날아가지 않고, 유지하여 보관할 수 있는 장치를 의미합니다.
- Read-only memory (ROM): programmed during production
- Programmable ROM (PROM): can be programmed once
- Erasable PROM (EPROM): can be bulk erased
- Electrically erasable PROM (EEPROM): electronic erase capability
- Flash memory: EEPROMs. with partial (block-level) erase capability
- SSDs(Solid-state disks): Disk-drive처럼 container 형태로 되어 있습니다.
- USB drives
- Surface-mounted on Motherboard: 대부분의 임베디드 시스템 ex) 휴대폰의 용량은 미리 정해져서 생산됨!
👍장점
- HDDs에 비해 더 reliable하고 빠르다
- 물리적인 움직임을 요하지 않기 때문에, seek time과 rotational latency가 없다
- Random access가 가능하다
👎단점
- 좀 더 비싸고, capacity가 작다
- Life span이 짧아, 관리에 유의해야 한다
- 한정된 횟수만큼만 erase할 수 있고, 이를 넘으면 닳아 없어질 수도 있다는 문제가 있다
PCI의 빠른 data transfer 속도를 활용하기 위해서
PCI slot에 SSD를 꽂아 사용하는 경우도 있다고 합니다.
Solid State Disk (SSD)

SSD는 I/O bus를 통해서 CPU와 연결되어 있다.
내부에 Flash Translation layer를 통해서,
request를 받으면 실제 데이터에 접근할 수 있도록 번역을 수행함
SSD는 여러 개의 Block으로 나뉘고, 각 Block은 여러 개의 Page로 나뉘어진다.
Pages: 512KB ~ 4KB
Blocks: 32~128 pages
Page 단위로 데이터를 주고 받는데,
덮어쓰는 것이 불가능하므로 그 전에 해당하는 Block을 erase해야한다.
이는 닳아버리기 때문에, 골고루 block을 활용하는 것이 중요하다.

NAND Flash Controller

- Logical Blcok을 가지고 있는 Physical page로의 번역을 수행하는 Flash Translation Layer(FTL)이 존재
- Invalid page space를 free 처리해주기 위한 Garbege collection이 구현
- Allocate overprovisioning: GC를 위한 임시 보관 공간이 필요. Block을 통째로 Clear 해줘야 하기 때문에, Valid page는 따로 모아서 저장해두고 처리
- Wear leveling: 닳을 수 있기 때문에, 각 block이 얼마나 erase되는지 Check
HDD Scheduling
데이터를 읽고자하는 여러개의 request, 어떻게 스케줄링해야 최적의 움직임으로 데이터를 읽어낼 수 있을까?
HDD scheduling의 목표는 Minimize seek time
Process가 I/O가 필요함. derive에 요청(System call: read, write ...)
Drive가 idle 상태라면 즉각적으로 처리되겠지만,
busy 상태라면 Queue에 추가되어 기다린다.
이후 해당 Management는 Storage devices/controller 내에 자체적으로 구현이 되어 있다!
해당 queue를 관리하기 위한 small buffer를 사용한다.
따라서 OS는 Logical block address(LBA)를 넘겨주면 Device에서 알아서 맞는 데이터를 꺼내준다.
이때 I/O request에는
- 해당 operation이 input인지 output인지
- 어떤 파일을 작동시키기 위함인지 open file handle
- 어떤 메모리를 올릴 건지 address
- 얼마만큼의 데이터를 올릴 건지
에 대한 내용이 포함된다
▶FCFS Scheduling
request가 들어온 순서대로 처리하는 방식이다.

👍장점👍
모든 request를 공평하게 처리한다.
👎단점👎
속도가 빠르지는 않다.
▶SCAN Algorithm
엘레베이터가 움직이듯이, 한 방향으로 출발했다가 끝에 도달하면 반대 방향으로 향하는 방식이다.
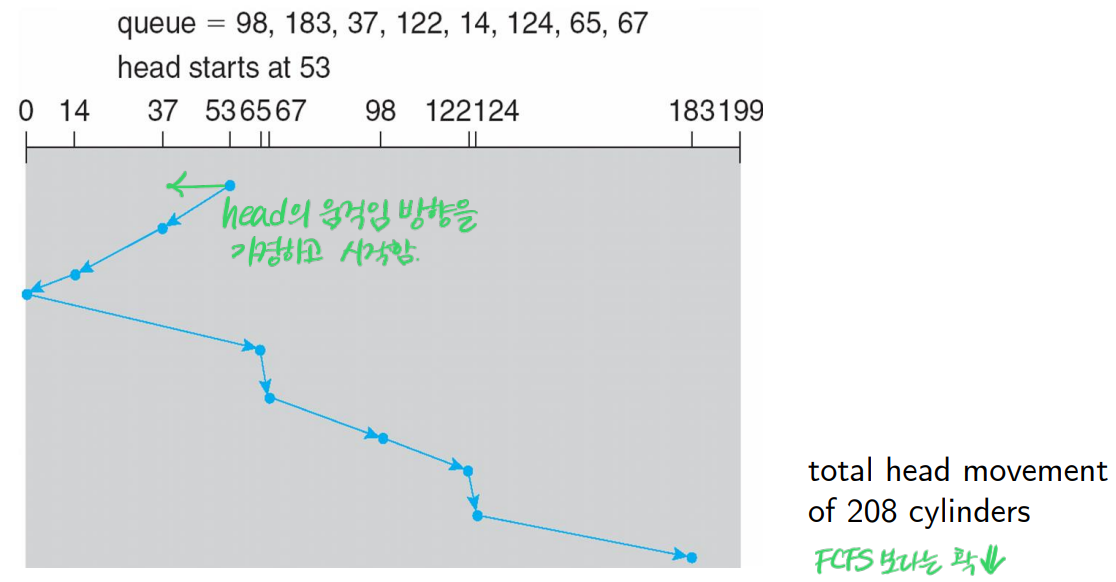
▶C-SCAN Scheduling
SCAN Algorithm과 유사한 형태이긴 한데 더 uniform한 형태라고 이해하면 된다.
끝에 도달했을 경우, 바로 그 반대편에서 검색을 시작하며
반대편으로 이동하는 과정에서 search을 진행하지 않는다.

Error Detection and Correction
bit flipping과 같이, 저장된 데이터에서 문제가 발생한 것을 의미한다.
이런 경우 detection, operation은 중단된다.
어떻게 error를 검출할까?
Parity Bit
데이터 Bit의 갯수를 세어,
1의 개수가 짝수라면 0, 홀수라면 1의 값을 가진다.
이를 통해 bit flipping이 발생한 경우를 감지한다.
그러나, 해당 Flipping 오류가 어디에서 발생한지는 알 수 없으므로 수정하는 작업은 불가능하다.
Error-Correction Code(ECC)
해당 오류가 단순한 형태일 경우, 감지하고 Correction을 수행합니다.
Storage Device Management
Low-level Formatting(Physical formatting)
Disk를 sector로 나누어 읽고 쓸 수 있도록 합니다.
이때 각 sector는 header information, error-correction code(ECC) 등을 가집니다.
Logical Formatting
Sector 단위로 나누어진 Disk위에 파일 단위로 관리할 수 있는 시스템인 File system을 생성합니다.
File에 대한 directory structure, meta data등의 데이터가 필요하다.

2개의 OS를 사용한다던지 할때 Disk를 Partition으로 나누어 사용하기도 하고,
효율성 증대를 위해 Blocks를 묶어 Clusters로 사용하기도 한다.
Booting 과정은 어떻게 될까?

Root partition이 OS를 포함하며, 부팅 시간에 자동으로 mounted된다.
OS root parition이 사용 가능한 상태가 되고, OS를 읽어 kernel을 돌리는 것임
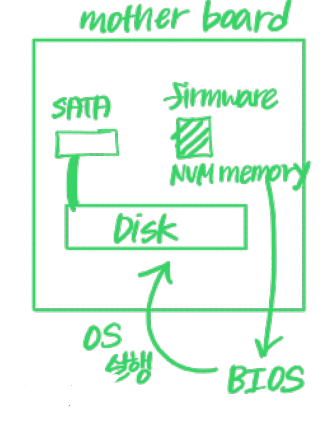

Booting을 하게 되면, mother board 위에 있는 BIOS 코드가 실행된다.
해당 BIOS 코드가 Partition table에서 Boot partition의 위치를 읽어서 접근한다.
(Bootstrap stored in NVM flash memory fireware)
해당 과정으로 실제 Disk에 있는 OS를 불러와서, 실제 kernel code를 읽어낸다.
Swap-Space Management
Operatign System이 제공한다.
DRAM이 부족할 경우, 해당 Process또는 Page의 내용을 보조 storage로 이동한다.
이때 Secondary storage의 속도가 더 느리기 때문에, 이를 최적화하기 위한 관리다.
1) Raw partition, 2) file로 swap을 수행한다.

Storage Attachment
컴퓨터는 다양한 방식으로 storage에 접근한다
- Local I/O part를 통한 Host-attached
- Remote Procedure Calls(RPCs)를 통한 Network-attached
- Cloud
RAID (Redundant Array of Inexpensive Disks)
저렴한 Disk을 Array로 낭낭하게 묶어 사용하므로서, 성능과 안정성을 향상시키기 위함!
그러면 걍 여러 디스크 사용하는 Multiple Disk와 비슷한거 아니야??
ㄴㄴ

Multiple Disks의 경우, 서로 다른 Disk는 각자만의 Block을 가지게 된다
RAID의 경우 서로 다른 Disk라고 해도, 해당 Block이 고루고루 분배(Striping)되어 하나의 Disk처럼 작동하게 된다.
이를 통해 0, 1, 2, 3 block을 동시에 접근할 수 있게 된다는 장점이 존재한다!
해당 RAID에 따라오는 몇가지 개념이 있다
- Mean Time Between Failures (MTBT)
- Mean Time to Repair: 또 다른 문제로 인해 데이터 손실이 발생할 수 있는 노출 시간
- Mean Time to Data Loss: 위 2개 요인에 기반함
먼저 Disk의 안정성을 보장하기 위한 가장 간단하고 (비싼) 방법은
모든 Drive를 복제해두는 것이나, 현실적으로 너무 비효율적이다
따라서 RAID는 redundant data를 두는 방식을 택한다
▶RAID 0 ( non-redundant striping )
Disk의 백업을 해두지 않고, 성능만 향상시키는 방식이다.
▶RAID 1 (Mirroring / Shadowing)
Redundancy data를 통해 안정성을 높인다.

따라서 위의 2개를 응용하여 높은 성능/안정성을 제공하기도 한다.
RAID 1+0 (Striped Mirrors)
RAID 0+1 (Mirrored Stripes)

즉 Mirroring 을 먼저하느냐 Striping을 먼저 하느냐 그 차이임.
만약 Disk가 불량이 나게 되면
Raid 1+0(Raid10) 의 경우, 이미 Mirroring 후 Striping을 진행하므로 Mirroring으로 묶인 하드로 손실된 데이터만 복원이 가능.
하지만, Raid 0+1(Raid01) 의 경우, Mirroring 전 Striping을 진행하므로 Disk가 불량이 나면 Grouping(RAID0로 구성) 된 Data 전체를 복구
그러므로 실제 동작할 때는 RAID 1+0 구성이 훨씬 유리하다고 하네요
▶RAID 4, 5, 6 (Block Interleaved Parity)

Disk의 data에 오류가 발생했는지 확인하기 위한
Parity Bit을 위해서 Redundancy data를 활용합니다.
RAID의 넘버가 올라갈 수록 더 복잡한 error 문제를 해결하기 위함이라는 것을 확인할 수 있음!
'STUDY > 운영체제' 카테고리의 다른 글
| [OS] Chap13. File-System Interface (0) | 2023.12.13 |
|---|---|
| [OS] Chap12. I/O Systems (0) | 2023.12.08 |
| [OS] Chap10. Virtual Memory (1) | 2023.12.03 |
| [OS] Chap09. Main Memory (0) | 2023.11.30 |
| [OS] Chap07. Synchronization Example (0) | 2023.10.18 |